Datasets
This page links to datasets made by my lab. Please see the individual project pages linked below to download or learn more about each dataset.
BloomVQA

[Dataset Website] [ACL Findings Paper]
COCO-OOC

[Dataset Website] [IJCAI Paper]
Biased MNIST
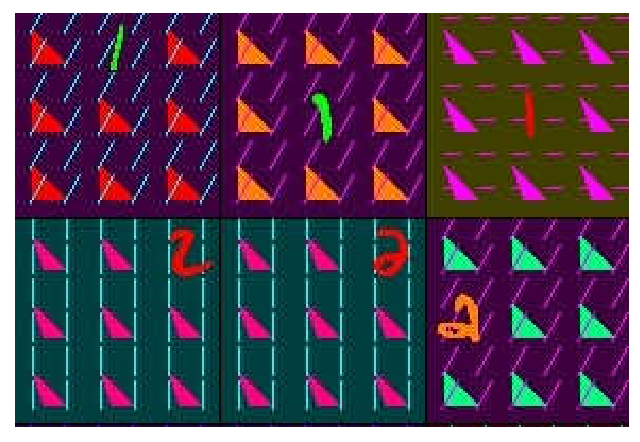
[Dataset Website] [ECCV Paper]
Stream-51
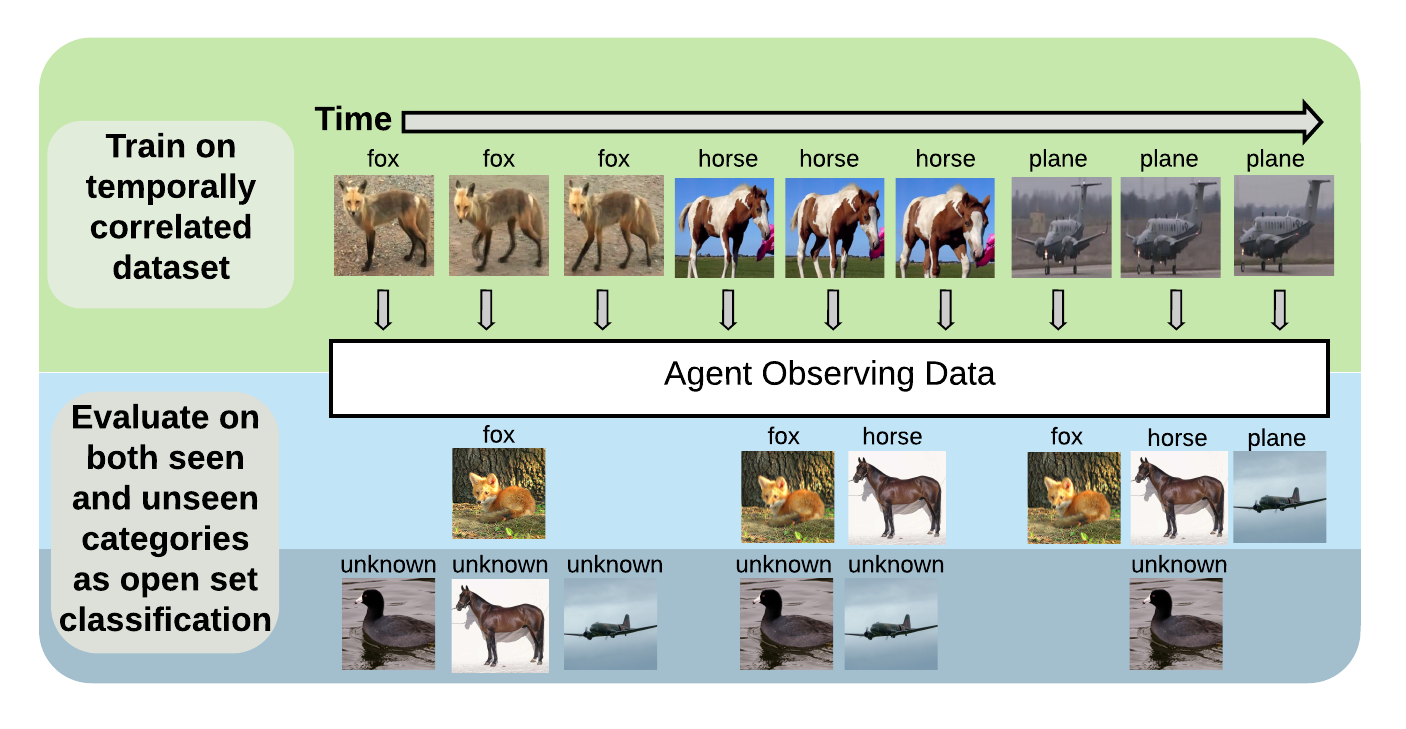
[Dataset Website] [CLVISION Paper]
Visual Query Detection v1 (VQDv1)
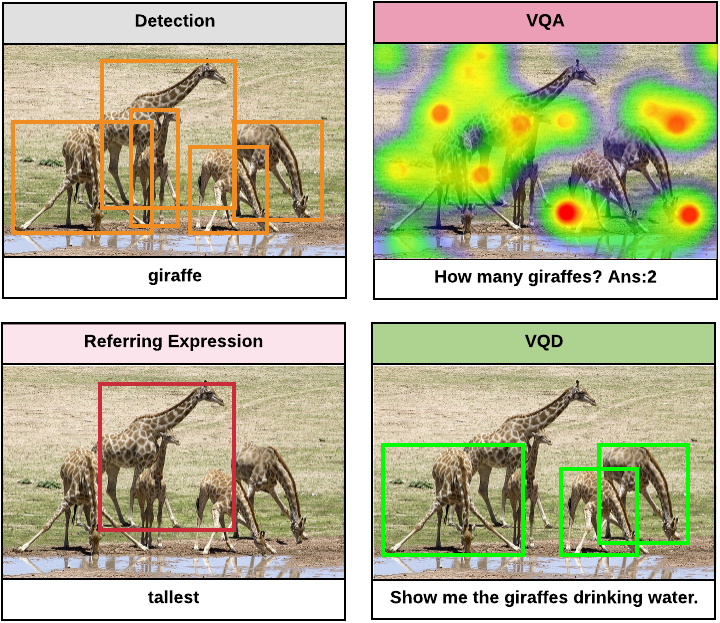
[Dataset Website] [NAACL Paper]
TallyQA
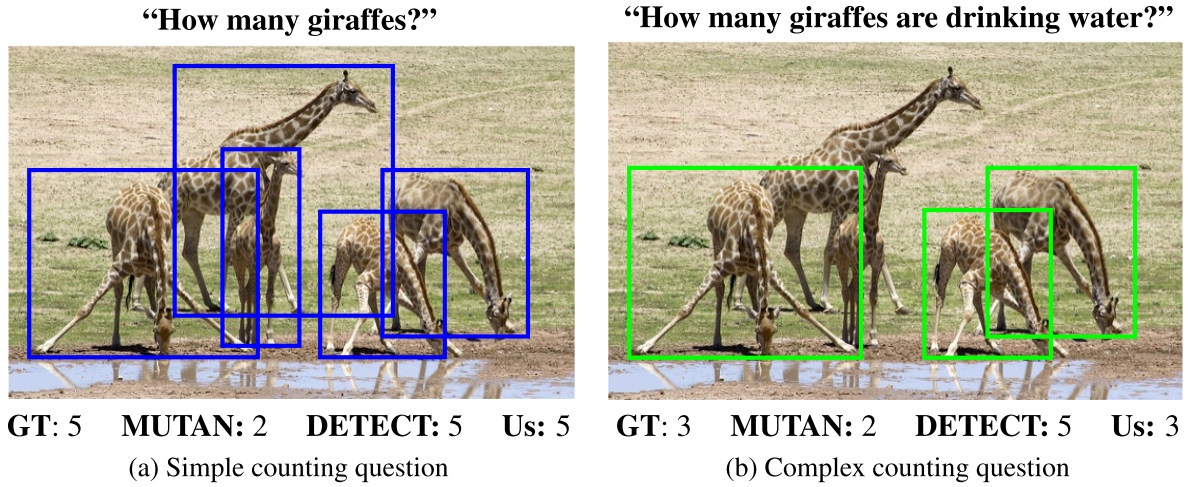
[Dataset Website] [AAAI Paper]
AeroRIT
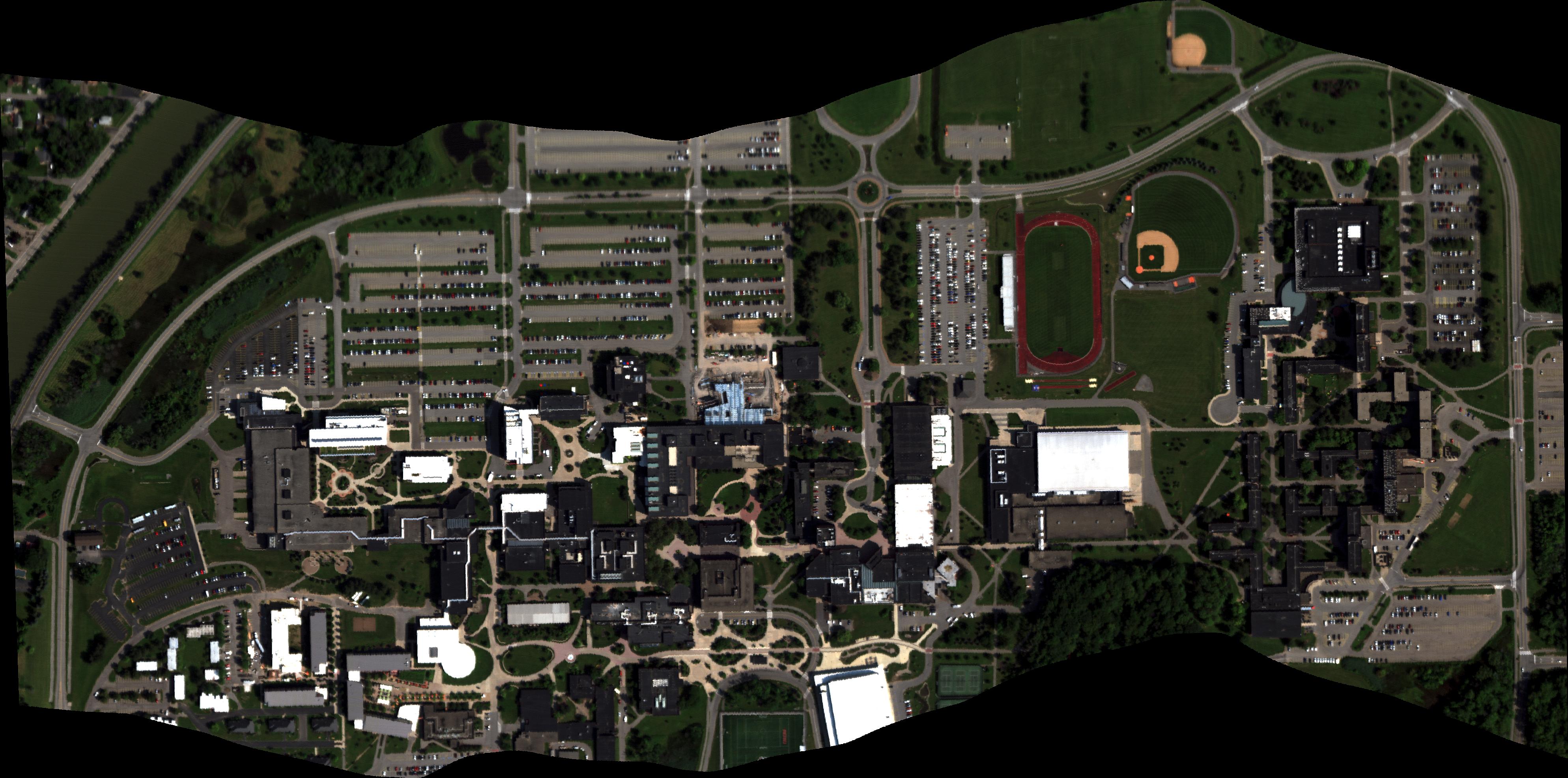
[Dataset Website] [TGRS Paper]
DVQA
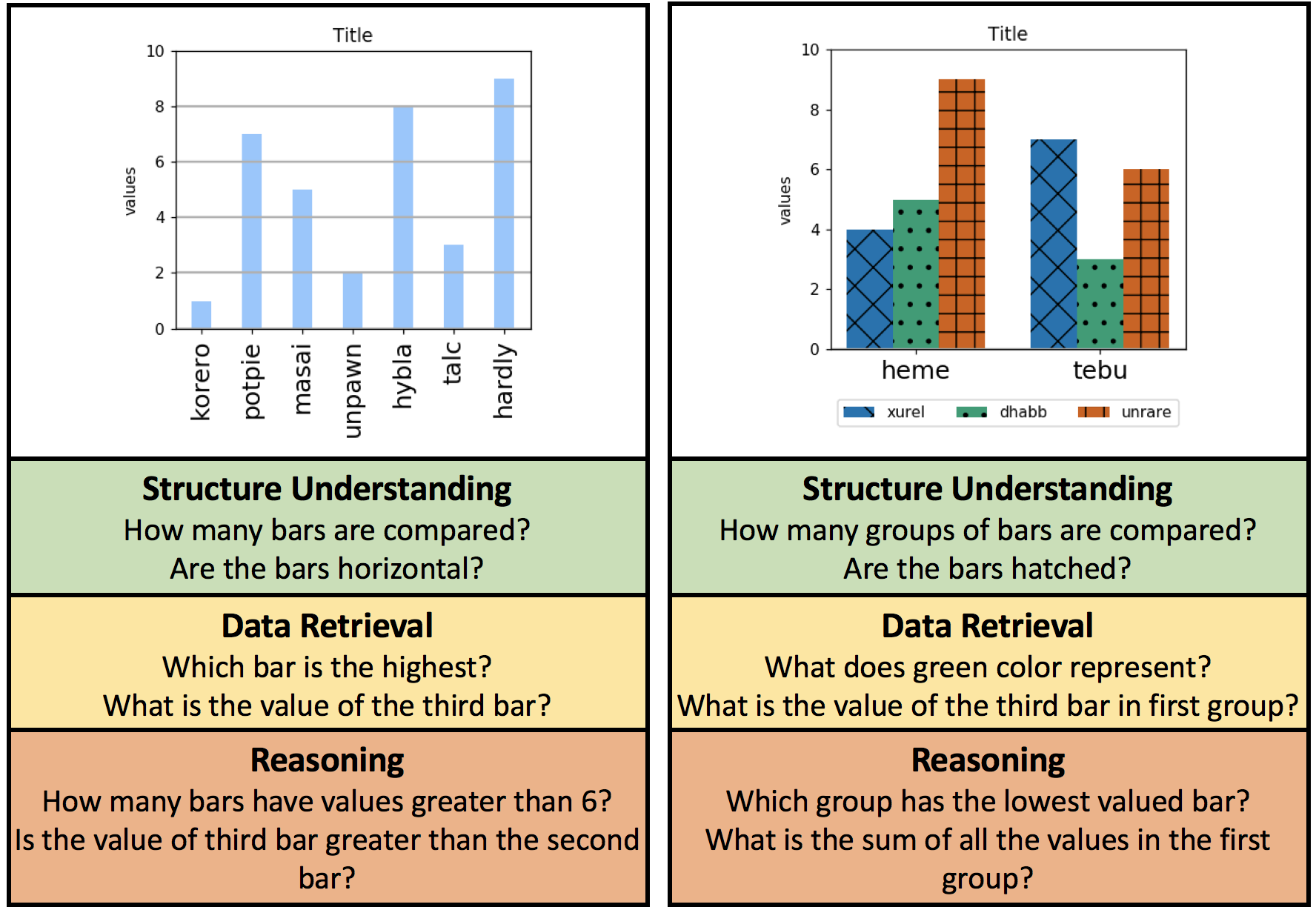
[Dataset Website] [CVPR Paper]
TDIUC: Task-driven image understanding challenge

[Dataset Website] [ICCV Paper]
RIT-18

[Dataset Website] [JPRS Paper]
VAIS
